Towards Detection and Remediation of Phonemic Confusion
Motivation
Ensuring that interactive NLP applications, such as dialogue systems, communicate clearly and effectively is critical to their long-term success and viability, especially in high-stakes domains, such as healthcare. Successful systems should thus seek to reduce communication breakdown.
One aspect of successful communication is the degree to which each party understands the other. For example, properly diagnosing a patient may necessitate asking logically complex questions, but these questions should be phrased as clearly as possible to promote understanding and mitigate confusion.
In this work, we specifically target phonemic confusion, that is, the misidentification of heard phonemes by a listener.
Overview
To reduce confusion-related communication breakdown, we propose that generative NLP systems integrate a novel confusion-mitigation framework into their natural language generation (NLG) processes (see figure below).
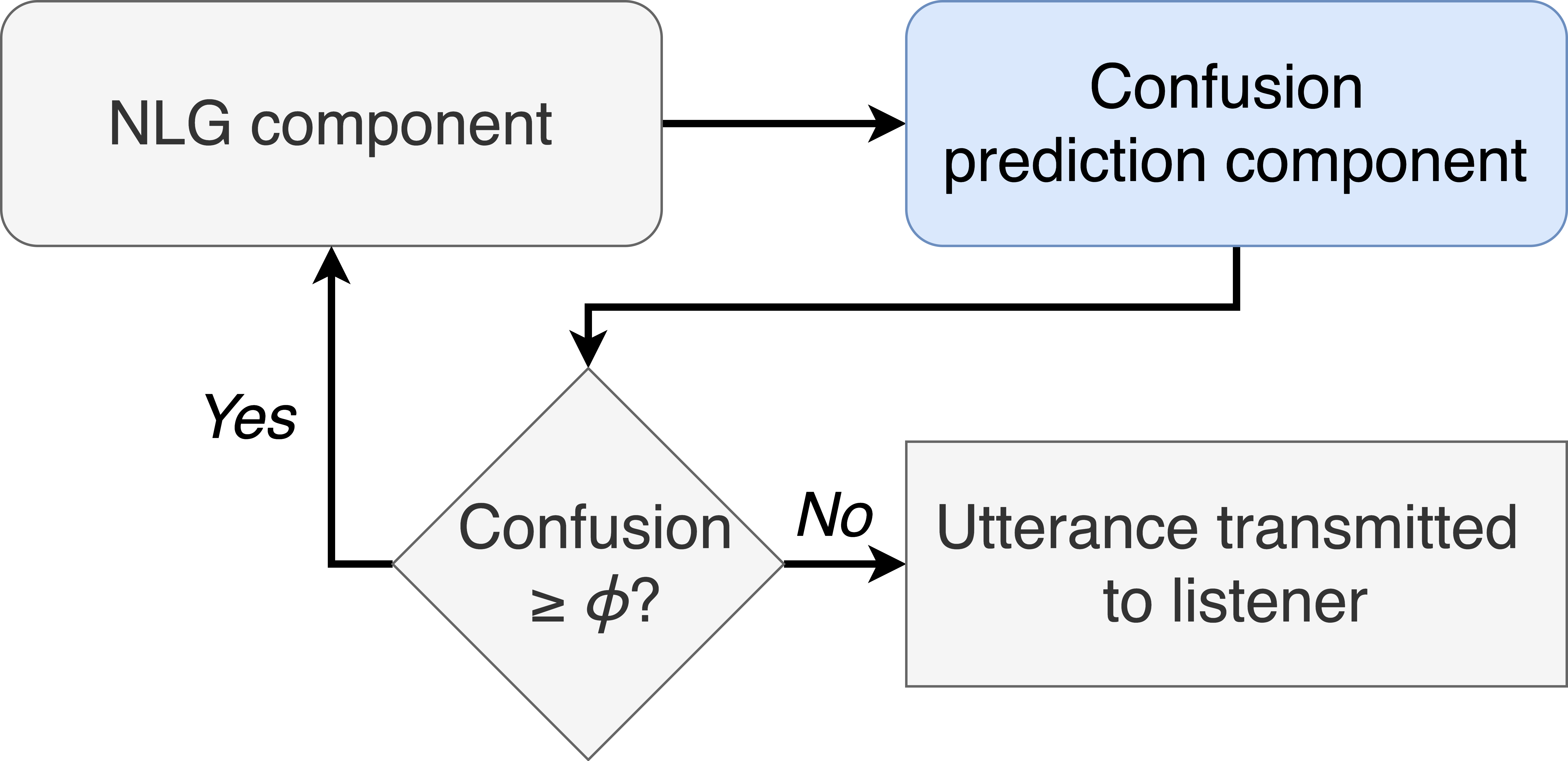
This framework ensures that NLG systems avoid generating statements with a high predicted probability of confusing the listener. In its simplest and most decoupled form, an existing NLG component simply produces alternative phrasings of each statement, and the least confusing is transmitted to the listener. In its more advanced and coupled form, the NLG and confusion prediction components can be closely integrated to better determine precisely how to avoid confusion. This process can even be conditioned on the current listener and task to achieve personalized and context-dependent results.
Experimental Results
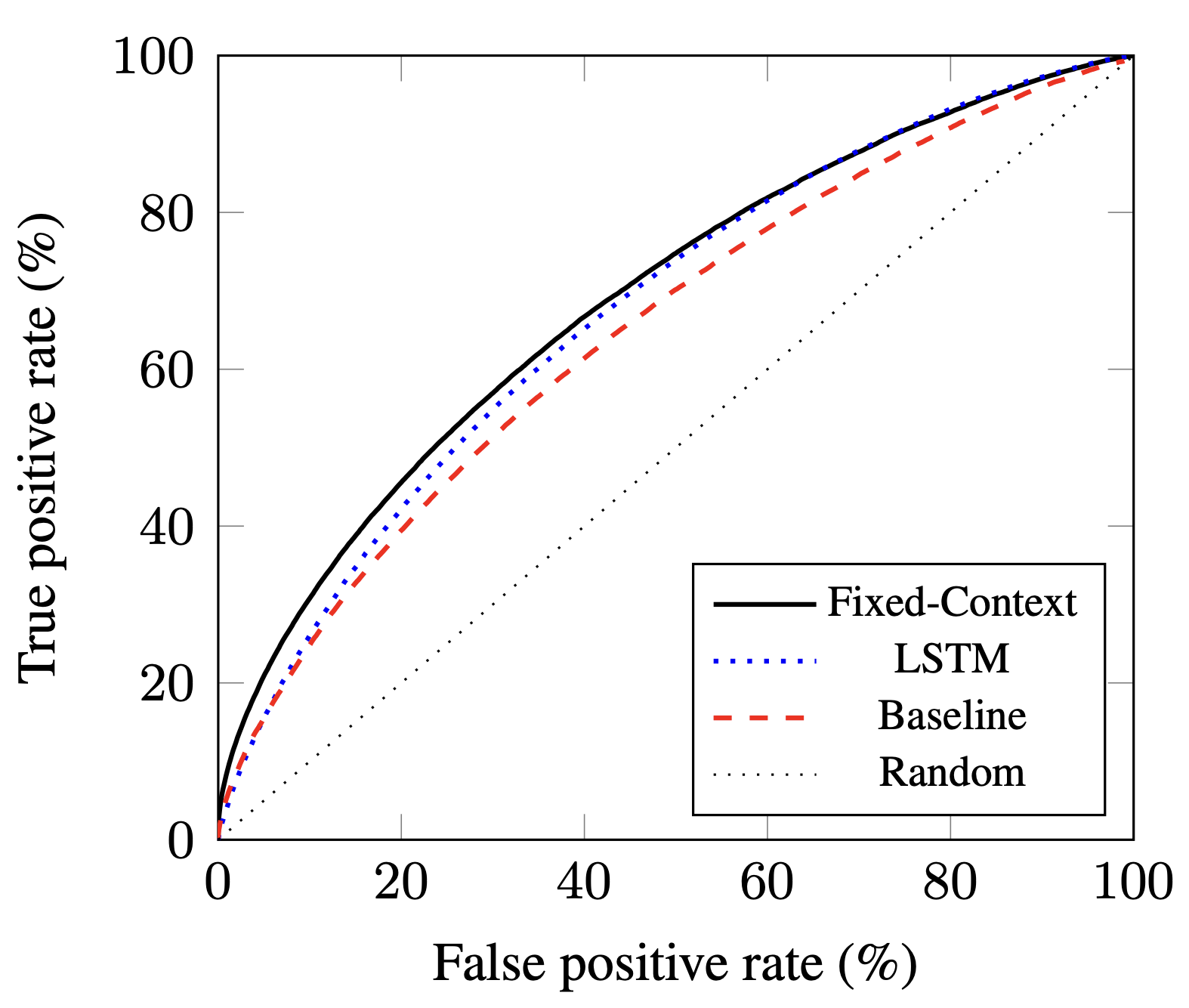
As a first step towards implementing this framework, we work towards developing its central confusion prediction component, which predicts the confusion probability of an utterance. We consider two potential neural architectures for this purpose: a fixed-context, feed-forward network and a residual, bidirectional LSTM network. We compare their performance to that of a weighted n-gram baseline.
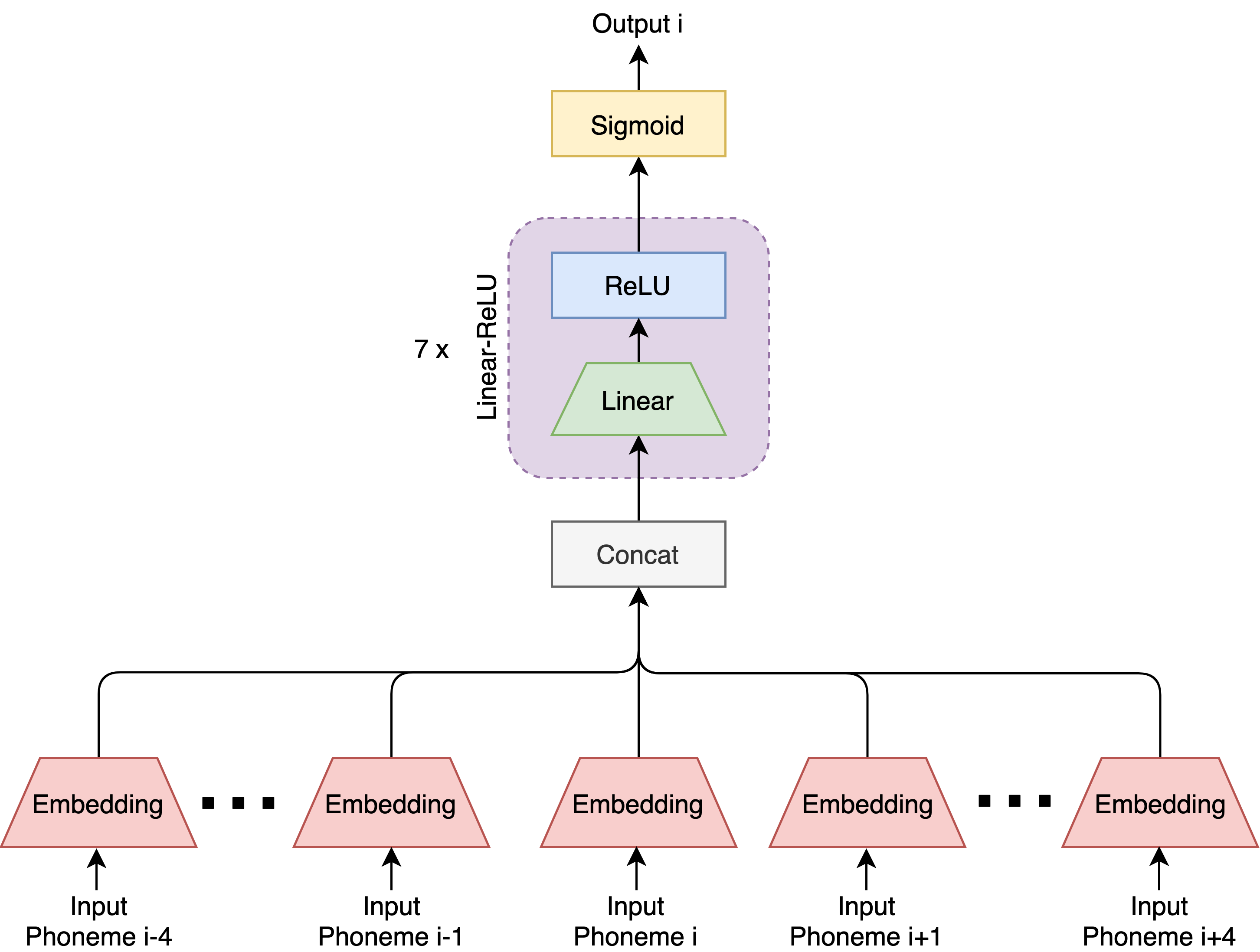
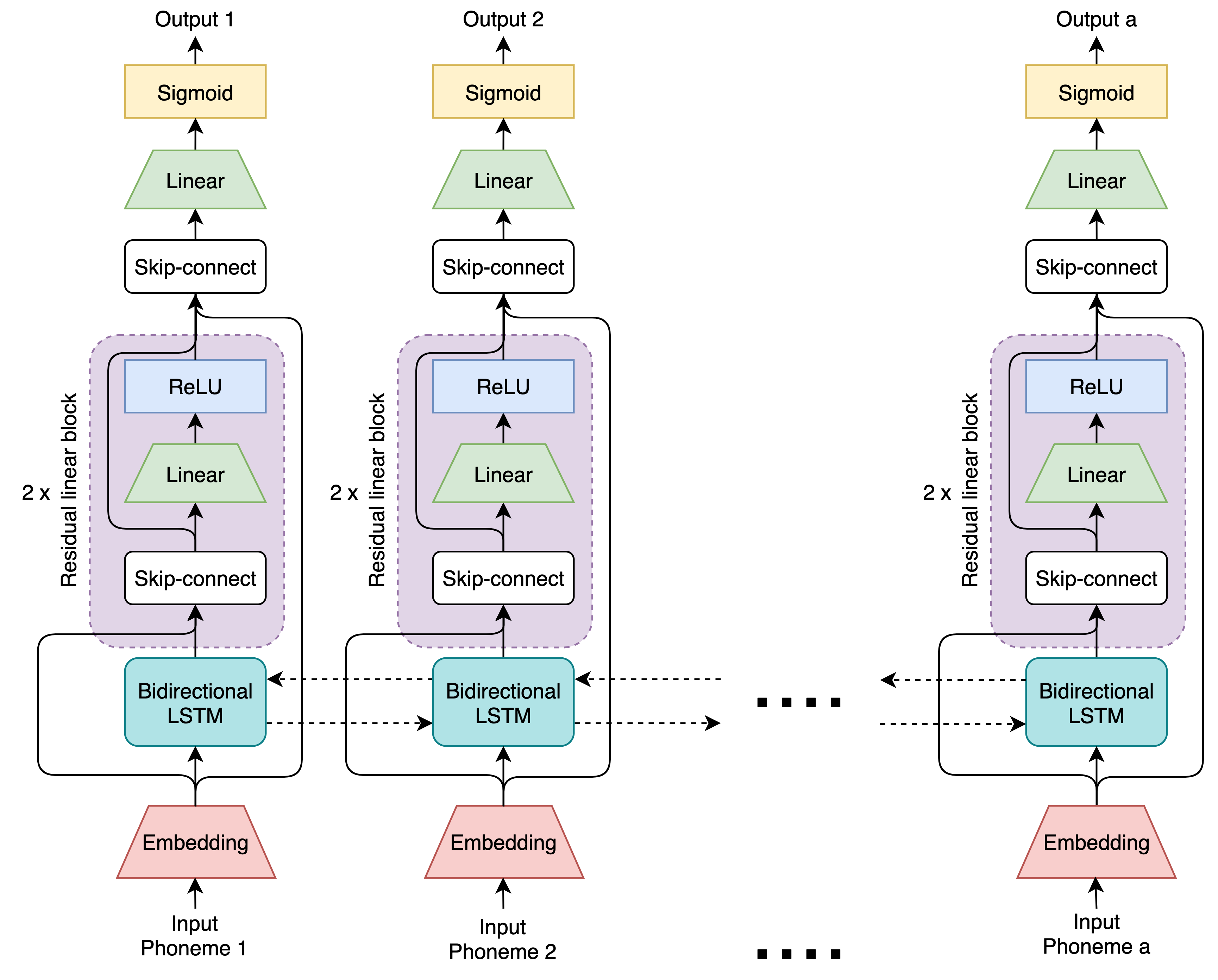
We train these models using a novel proxy data set derived from audiobook recordings. Specifically, we create a new data set with parallel reference and hypothesis transcriptions from existing audiobook data that contains parallel text and audio recordings. The text directly becomes the reference transcriptions. A transcriber is used to convert the audio recordings into hypothesis transcriptions. We used an automatic speech recognition (ASR) system as a proxy for human transcribers in this proof-of-concept work.

Our results show that both neural models outperform a weighted n-gram baseline, and significantly outperform random chance, showing early promise for the broader framework.