ACCORD: Closing the Commonsense Measurability Gap
Update!
ACCORD received an Outstanding Paper Award at NAACL 2025.
Motivation
Our understanding of large language models’ (LLMs) commonsense reasoning abilities is severely lagging compared to our understanding of their formal reasoning abilities, such as in logic or math. Specifically, commonsense benchmarks are difficult to construct in a manner that is rigorously quantifiable. As such, key players in AI have singled out commonsense as a critical new frontier.
Prior commonsense reasoning benchmarks and datasets are limited to one- or two-hop reasoning or include an unknown (i.e., non-measurable) number of reasoning hops and/or distractors. In contrast, formal reasoning benchmarks typically have excellent control over a wide range of reasoning complexity levels. Most prior benchmarks are also commonsense aligned, which unfortunately enables LLMs to spuriously ‘guess’ correct answers without having to properly reasoning through a question.
ACCORD is a framework for generating Anti-faCtual COmmonsense Reasoning Disentanglement benchmarks. ACCORD introduces formal elements to commonsense reasoning, and thus takes a significant step towards closing the commonsense measurability gap with respect to formal reasoning.
Overview
ACCORD tightly controls fine-grained counterfactual variants of commonsense reasoning tasks to enable detailed analysis of large language model (LLM) performance factors. In particular, ACCORD disentangles commonsense grounding and reasoning abilities in LLMs, while controlling for both reasoning complexity (via increased reasoning hops), reasoning skills (since some skills may be harder than others to learn), and distractors (since real-world text is imperfect and often contains distracting elements). The ability to quantify and control these factors is ubiquitous in formal reasoning benchmarks, but overwhelmingly lacking in commonsense reasoning benchmarks.
ACCORD instances are grounded counterfactually (more accurate, anti-factually) to mitigate LLMs’ ability to spuriously ‘guess’ correct answers thereby shortcutting the intended reasoning task. In addition, ACCORD is uniquely designed to automatically scale its difficulty level in tandem with future LLM improvements by leveraging compositional scalability to generate future benchmarks of arbitrary reasoning complexity with minimal additional human effort. Arbitrary scalability via compositional construction is somewhat typical of formal reasoning tasks but lacking in commonsense reasoning.
Our paper discusses these features in great detail, and our codebase can both reproduce our benchmark suite and generate more challenging future benchmarks. The official benchmark suite can also be downloaded from our leaderboard website.
Experimental Results
We benchmarked 3 state-of-the-art LLMs in our paper: gpt-4o-2024-05-13, Meta-Llama-3-70B-Instruct, and Mixtral-8x22B-Instruct-v0.1. The results are shown in the figure below.
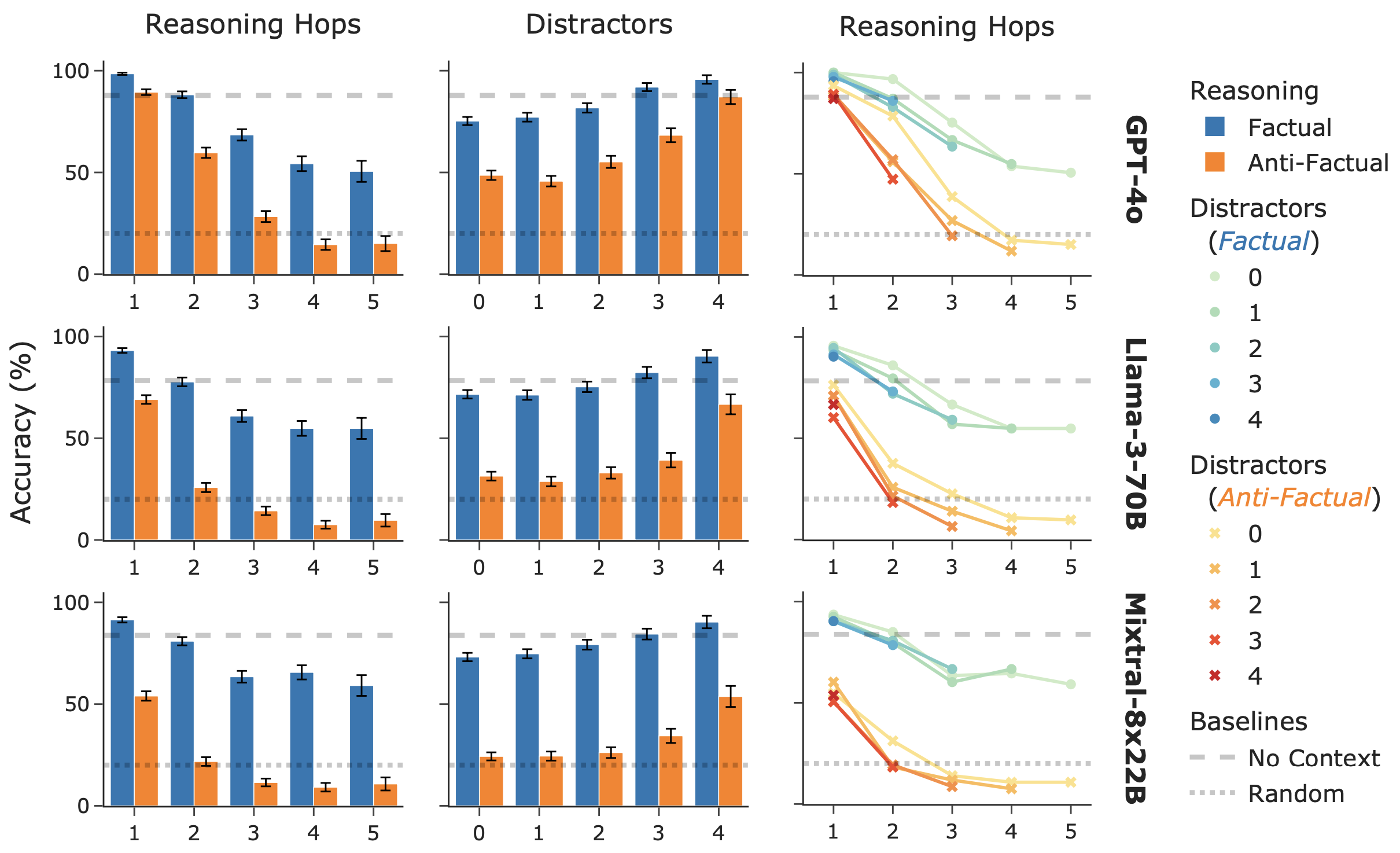
We broke down LLM performance as a function of both reasoning complexity (Column 1) and distraction complexity (Column 2). This ability is unique to ACCORD amongst commonsense reasoning benchmarks. We see that performance quickly degrades as reasoning complexity increases, indicating that LLMs struggle with multi-hop commonsense reasoning beyond just a few hops.
Distractor performance shows the reverse trend. This occurs because, by construction, ACCORD has a fixed context budget, which means that more distractors leads to fewer reasoning hops. Column 3 illustrates this interaction effect. Specifically, when controlling for distractors, reasoning hops have a dominant effect on the trend. On the other hand, increasing distractors only slightly shifts the entire trend line downward. In other words, given a fixed context budget, LLMs tend to prefer more distractors and little reasoning than the reverse. That is, the ability of LLMs to filter out distractors significantly outclasses their multi-hop reasoning capacity. Marginalizing over reasoning hops obfuscates this nuance, hence the reversed trend for distractors in Column 2. Being able to disentangle these effects is one of our key contributions.
For each complexity level, we additionally compared performance on commonsense-aligned (i.e., factual) and commonsense-misaligned (i.e., anti-factual) variants of the same underlying task. Since we are carefully controlling for all other factors, this performance gap is directly indicative of spurious answer guessing: LLMs are inductively biased towards the factual answer choice. In fact, anti-factual performance quickly degrades to below random chance with only very moderate scaling of reasoning complexity, whereas factual performance decreases but remains significantly above random chance. This suggests that, as soon as their multi-hop reasoning capacity is exceeded, LLMs almost exclusively resort to spurious guessing, indicating a need for substantial improvement in LLMs’ commonsense reasoning capacity as a key next step to improve overall LLM performance.
Tips for Benchmarking Your LLM
For benchmarking your own LLM, download the official benchmark release from the leaderboard website. We encourage submission to the leaderboard to record your LLMs’ performance against that of others. Instructions can be found on the leaderboard website.